Table of Contents
In one of my last posts, I wrote about attribution in cybersecurity, i.e. ways to find out who was behind an attack. One particular class of attackers are so-called APTs: Advanced Persistent Threats. These APT groups dispose of considerable amounts of resources (time, money, personnel, etc.) to attack their target. As part of their attacks they will often employ malware that can be remotely controlled from a C&C (command & control, also often abbreviated as “C2”) server. These allow to load additional functionality, to access infected systems and to exfiltrate stolen data.
C&C servers are also interesting for defenders: Searching and finding such servers proactively allows to detect and possibly stop attacks early on and in some cases, forensic analysis of C&C servers helps to attribute a certain attack campaign to a specific APT.
NIST Computer Security Incident Handling Guide
The US National Institute of Standards and Technology (NIST) has published many different papers on cybersecurity. Special publication (SP) 800-61 from 2012 contains the Computer Security Incident Handling Guide. It explains how companies can detect and act on cybersecurity incidents.
Attribution – finding out the “who” behind an (attempted) attack – will not be a priority for the “average Joe company”. However, for threat intelligence providers, national security agencies and criminal prosecutors alike, attribution can be critical. In a previous blog post I listed different reasons for the importance of attribution, so I will not go into detail here. This being said, with cyberattacks having lethal consequences, the importance to gather enough information and to perform attribution only rises also for non-security companies. NIST SP 800-61 therefore states under “Evidence Gathering and Handling”:
“Although the primary reason for gathering evidence during an incident is to resolve the incident, it may also be needed for legal proceedings.”
(Cichonski et al., 2012, p. 36)
Proactively finding C&C servers is certainly not a task for the “normal”, non-security company that is focusing on its main business (retailers selling goods, travel agencies selling trips etc.). Instead, specialized cybersecurity companies that assemble threat intelligence and early warning feeds will be acting in this realm – apart from state actors. One idea of threat intelligence is that companies can subscribe to up-to-date feeds and compare network traffic to known “bad” IPs.
A “normal” (non-security) company might for example monitor URLs from internal DNS servers and web proxies, as well as IP addresses logged by firewalls. Without further information, it is hard to understand if a connection attempt is suspicious or not. Therefore, many companies subscribe to threat intelligence feeds like IBM X-Force Exchange, AlienVault Threat Exchange, or Fortinet FortiGuard, to name just a few. These provide risk scores for known “bad” resources. With such additional data, companies can then compare each of the observed URLs and IPs to the long list from their threat intelligence feed to check if any of the accessed resources is known to be malicious. If it is found that an internal system is continuously communicating with an IP that is a known C&C server, alarm bells should ring.
NIST SP 800-61 describes such feeds as “Third-party monitoring services” and recommends them as one source of information to detect signs of an incident. The publication differentiates between so-called “precursors” and “indicators”.
Precursors
NIST defines precursors as follows:
“A precursor is a sign that an incident may occur in the future.
[…]
Most attacks do not have any identifiable or detectable precursors from the target’s perspective. If precursors are detected, the organization may have an opportunity to prevent the incident by altering its security posture to save a target from attack.”
(Cichonski et al., 2012, p. 26)
What NIST calls precursors is often marketed as “early-warning feed” in the security industry. The idea is to find signs of an attack and counteract before anything happened.
Indicators
As you might have guessed, an indicator, as opposed to a precursor, is evidence gathered “after the fact”:
“An indicator is a sign that an incident may have occurred or may be occurring now.
[…]
While precursors are relatively rare, indicators are all too common.”
(Cichonski et al., 2012, p. 26)
Any IDS or antivirus alert, as well as matches of network traffic against the aforementioned threat intelligence feeds would be examples for indicators of an attack.
Finding Malicious Servers
Then, how do threat intel companies know which IPs are hijacked by C&C servers or otherwise malicious? Someone will have to find new threats, including corresponding IPs and URLs and flag them as risky. The following techniques are used by different threat intelligence companies to find such malicious servers.
A word of caution: Since speed is key when it comes to detecting and acting on arising threats, different threat intelligence feeds use automation to gather information from many different sources. The problem with this is that “just in case” automated risk scores are often copied from each other before actually verifying them. This can result in a quickly spreading false positive; it is not unheard of that a wrong entry on a rather unreliable platform like Twitter or Pastebin quickly propagates across many well-known early-warning feeds, simply because all that new information is automatically scraped and copied. Let’s therefore start with more reliable techniques where analysts manually gather intelligence.
Indicators from Static Program Analysis (Disassembly)
If a malware already exists, analysts can try to disassemble it to understand how the malware works and to find hardcoded target addresses for command & control servers. This technique is known as static program analysis, because it is not necessary to run the program. Examples for disassemblers are IDA Pro and Ghidra, the latter developed and made available to the public by the NSA.
Indicators from Dynamic Analysis (Sandboxing)
An alternative to static disassembly – which can be a quite lengthy process – is to intentionally infect a monitored system in a sandbox to watch its behaviour. This is known as dynamic program analysis. If analysts see that malware is starting to communicate with certain IPs or domains, it is likely that these form part of a malware network and that they should therefore be flagged as risky. An example would be the X-Force Exchange report on Dridex, where analysts found different URLs and IP addresses involved in malicious communication:
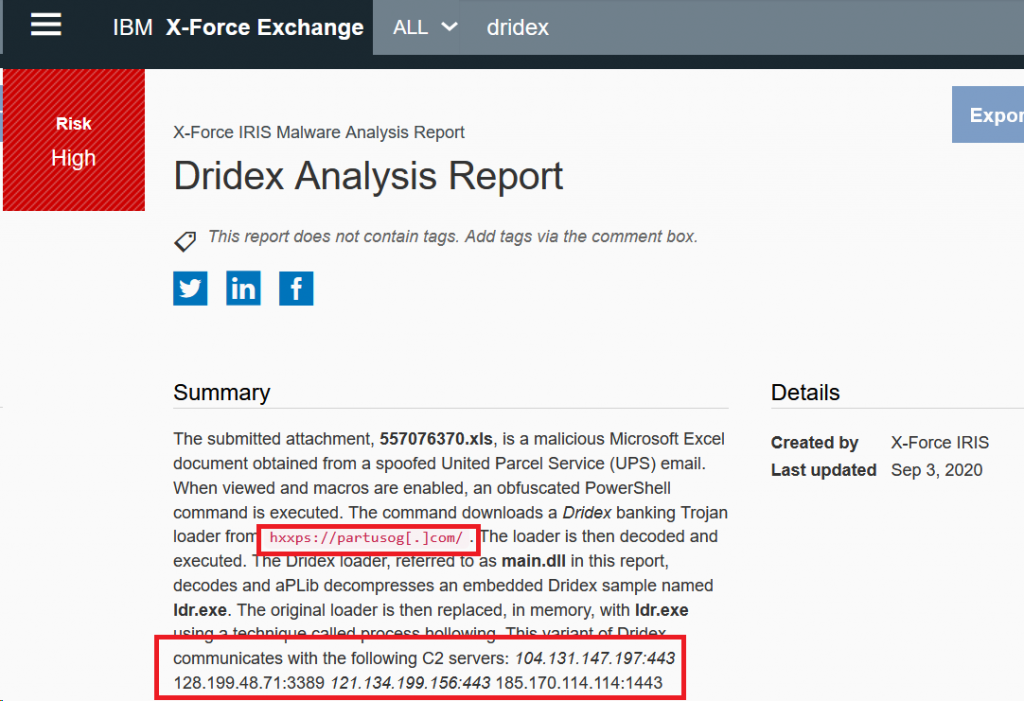
As a countermeasure, malware will try to detect if it is run inside a sandbox or not. Sandboxes often will not allow outgoing connections (to block the malware from spreading) but simply “fake” a positive response from whatever resource the malware is trying to access.
Malware uses this peculiarity to detect a sandbox: The malicious program will deliberately try to access a URL of which it knows that it does not exist. If it then receives a positive (faked) response, it knows that it is running in a sandbox and will stop working to prevent dynamic analysis. This can have ironic effects: If analysts – knowingly or not – find such “test domain” hardcoded somewhere in the malware and register it, the malware will stop working completely, because now that the “known to be non-existent” URL indeed exists, the whole world has suddenly become a “sandbox”. This is what happened for example with WannaCry, where the “kill switch” was basically to register such a random “non-existent URL”.
Precursors from Domain Generation Algorithms (DGAs)
Reverse Engineering as explained above – be it statically or dynamically – is usually quite accurate as the false positive rate is rather low. IPs and URLs found using these means of analysis are usually “real” dangerous IPs and URLs. The disadvantage is that malware already needs to exist and be active in order to have analysts finding and analysing it. It would be better of course if malicious resources could be found before they do any harm. One of these methods is called “Domain Generation Algorithm (DGA)” and it is basically trying to beat threat actors at their own game.
If IPs and URLs of malicious C&C servers are hardcoded into a malware’s source code, it can easily be detected through means of reverse engineering. DGAs instead use some kind of logic to dynamically create ad-hoc addresses. If the DGA is not completely random but deterministic, the malware author will know which domains the malware will be trying to connect. If the attacker then registers some of these automatically created URLs, he can point them to actual C&C servers. The rest of the dynamic addresses which are constantly created serve as distracting decoy, filling up DNS logs with non-existent URLs.
If analysts can find patterns in how these domains are created, they can proactively flag them as malicious. If a malware author at some point will register an address, it will already be flagged by threat intel services and connections will immediately raise an alert. Even if a URL remains non-existent, it can make sense to have alerts on connection attempts, because it is a sign that malware using such DGA is already present inside the victim’s network. The drawback is that finding deterministic patterns in DGA to proactively flag potential URLs is difficult and error-prone – many false positives are the result. Also, malware authors can simply change their DGA slightly and analysts will have to start all over again. It’s a cat-and-mouse game…
Precursors from Domain Squatting Detection
Threat actors might try to register domains that look very similar to legitimate domains. This activity, known as domain squatting, makes it less likely that malicious connections stand out in DNS monitoring and such squatted domains are also useful to create authentic-looking links as part of a phishing campaign. Ever wondered why gogle.com (with only one “o”) also belongs to Google and redirects to the real google.com? It’s to prevent domain squatting. Companies can use tools like dnstwist to create a long list of similar-looking domains, check if someone already registered them (and maybe file a take-down request) and proactively register domains that look or sound so similar that an attacker might want to use them.
For threat intelligence feeds, proactively registering such domains is often not a priority, but as part of an early warning system, newly registered domains are often – and fully automatically – scrutinized if their sole raison d’être seems to be domain squatting. In such case, the URL might equally be flagged as risky.
Precursors from Fake Page Detection
Apart from finding domains that look or sound very similar to a victim’s original domain, automation can also be used to find pages that are visually similar to the original website. Companies like Microsoft use automation to quickly detect fake login pages that are set up to be used for credential phishing. The results are quite impressive: If you set up a fake login page for Microsoft365 as part of a penetration testing engagement, it can well happen that Microsoft already filed a take-down request before you could even launch your social engineering campaign (as it happened to an acquaintance of mine). Of course, companies that crawl the web to discover such fake pages can directly add found URLs to threat intelligence feeds, so that activity monitoring can block connection attempts or alert users and security departments.
Precursors from unique behaviours by employed C&C software
Analysts can try to find specific behaviours of malicious software to identify it when scanning the web. The publicly available tool “Poison Ivy” was for example used by different attackers to serve as remote access trojan. Threat researchers found that Poison Ivy always answers with a response unique to that software:
“The scanner sends 100 times 0x00 to a specific port and IP. If in the response the server sends back 100 other bytes followed by the specific data 0x000015D0,we know that the running service is a Poison Ivy server.”
(Rascagneres, 2013, p. 6)
They could therefore scan the web to find more instances of that tool and to flag the hosting servers as potentially malicious. This technique of finding uniquely identifiable responses is also used by Shodan Malware Hunter to automatically find threats on the web.
Precursors from other domains on same DNS server
DNS servers are often not only responsible for serving one specific second-level domain, but for several ones. By finding one suspicious domain, it often is worth to have a look at other domains handled by the same DNS server. Especially for providers who accept more anonymous payment options than the traditional credit card – such as Bitcoin – scrolling through the list of managed domains can be a rich source for further threat intelligence.
Crowdstrike and other providers used this technique when investigating the Democratic National Committee cyber attacks from 2015 and 2016. They found further malicious domains and more hints about the attackers’ identity by sorting out legitimate domains served by the discovered DNS server, leaving them with a whole bunch of suspiciously looking registrations (e.g. cloudfiare[.]com that was intended to look like the legitimate cloudflare.com).
There are of course many other techniques that threat intelligence providers employ, but the list above should give a good overview on what can be done. Additionally, in the following section on attribution we will also see that techniques there can also be considered methods for finding further potentially malicious servers.
Attributing C&C Servers
In his very good book “Attribution of Advanced Persistent Threats“, Timo Steffens explains several ways on how defenders can track down C&C servers and how to use attackers’ traces to draw conclusions on their identity. These techniques can be used after an attack in order to support criminal prosecution, but it can also serve as additional information to enrich threat intelligence feeds.
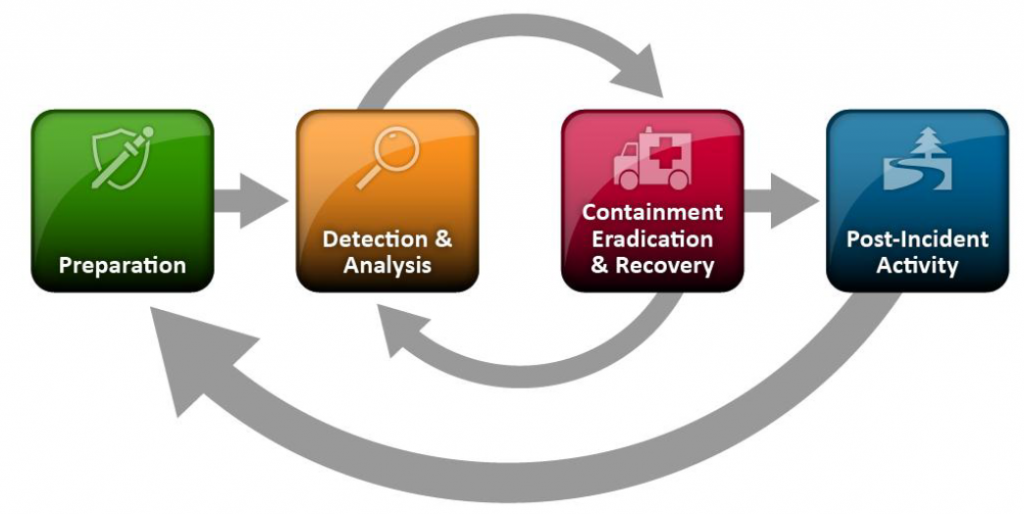
Considering the latter, we can understand attribution as one step in a repeating cycle where insights from attribution research can feed back into early-warning threat intelligence. This is also taken into account in the NIST Incident Response Life Cycle, where you see a bold arrow closing the loop from Post-Incident Activity (Attribution) back to Preparation (Threat Intelligence):
Hardcoded Server IPs
One pretty straightforward method for attribution is building upon the aforementioned static program analysis. If analysts found hardcoded IPs in a malware program, they can check if the IP is used by many different entities (multi-tenancy, typical for cloud storage), or if it is exclusively used by a single party. If the latter applies, it can be assumed that the attackers are running that server or that they at least hijacked it from an unaware third party. Of course, attackers might use several hops to jump from their real workstation via different intermediate hosts to that discovered target, but it is a first foothold that analysts can gain.
Domain Registration Data
Building upon the discovery of a C&C server IP or URL, analysts can now check domain registration data, using for example a WHOIS Lookup tool. Domain registration requires the person who registers a domain to enter valid registration data, including a real name and address. The ICANN which maintains this data as part of the Domain Name System explains on its website:
“If you give wrong information on purpose, or don’t update your information promptly if there is a change, your domain name registration may be suspended or even cancelled. This could also happen if you don’t respond to inquiries by your registrar if they contact you about the accuracy of your contact information.
(About WHOIS | ICANN WHOIS, n.d.)
When you register a domain name, you must give your registrar accurate and reliable contact details, and correct and update them promptly if there are any changes during the term of the registration period. This obligation is part of your registration agreement with the registrar.”
Registrants, including attackers, can use services to hide personal information. Such offers are not necessarily shady, because it is in many people’s interest to protect their privacy. Cloud service provider Amazon AWS for example has a feature that hides registrant details by default.
However, at least the “privacy guard” who replaces this information (e.g. Amazon) will need to have a valid email address and often also a valid credit card number of the registrant. While these may also be faked, they offer additional starting points for further investigation. In some cases, the same email address or credit card information has been used before – maybe even in a context where the attacker revealed further private information (e.g. on a forum, a social network, private online purchases, etc.).
Not all “privacy guards” will be willing to cooperate and reveal the real identity of their clients upon request, but as soon as their clients stop paying for their privacy services, they often put back the real information of the registrant. Such data helped for example researchers from Mandiant to identify hackers belonging to APT1.
Same registrant email address in other places
This technique is another example for “contributing both to attribution and proactive threat intelligence”. It takes advantage of the fact that in many cases an email address has a 1-to-1 relationship with a specific individual.
By crawling WHOIS directories and the web as a whole, analysts can try to find an email address from the DNS registrant data of a malicious site in the registrant data of other domains or on other web pages like forums. If the attacker used the same email address for the registration of other domains or on some website, real data might have been put in some of these registrations.
While this might sound like a rookie mistake, it does happen even to APT members, especially if they are under time pressure. Even if other registration data is also faked, seeing the additional domains for the same email address might allow analysts to draw a clearer picture of whom they are dealing with.
Instead of looking up data from many different sources manually, there are tools that harvest, normalize and index all this kind of information; a very popular tool is for example RiskIQ PassiveTotal. It also supports Passive DNS lookups, which are described next. Finding registrant email addresses and mapping them to other “personal” data helped TrendMicro to identify the actors behind a campaign called “Luckycat”:
“Additional clues concerning the attackers had to with the email address, 19013788@qq.com, which was used to register one of the C&C servers, clbest.greenglassint.net. This email address can be mapped to the QQ number, 19013788. QQ is popular instant-messaging (IM) software in China. This QQ number is linked to a hacker in the Chinese underground community who goes by the nickname, “dang0102,” and has published posts in the famous hacker forum, XFocus, in 2005.”
(Trend Micro, 2012, p. 11)
Passive DNS
Another way to find more information is to “go backwards”. The Domain Name System (DNS) works in such a way that if a user enters a domain like www.google.com, it will be translated into an internet-routable IP address which is needed to establish the connection. DNS is not designed to allow reverse lookups, i.e. to see all domains that resolve to a given IP. There is no global database that holds all combinations of “this domain belongs to this IP”, because DNS is a globally distributed (and therefore quite resilient) system.
Having such reverse lookup however could be very useful: While an attacker might hide registrant data as explained above for one domain, he might have forgotten to do so for another domain that translates to the same IP address. Seeing all domains that resolve to a known malicious IP address also helps to enrich threat intelligence feeds. How to perform such reverse lookups? Enter Passive DNS.
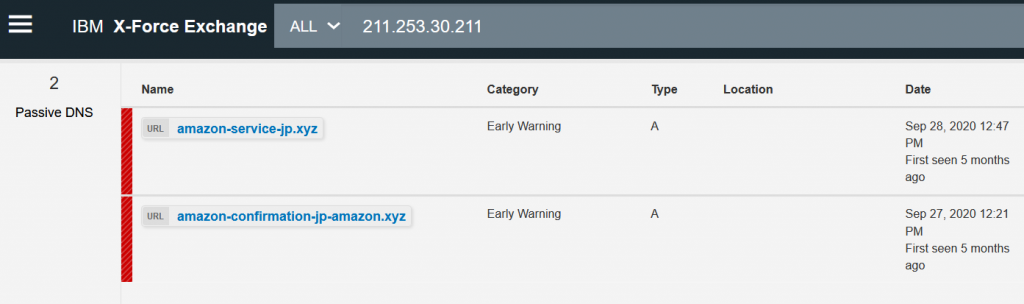
Providers of public DNS servers such as Quad9 anonymously record all forward lookups – i.e. they create a list of “which was the response (IP address) for a given domain?”. In a way, they create this kind of global DNS database which can be searched forward and backwards. Of course, such information can be outdated and it can only be recorded if there was a forward lookup at some point. However, once such list is created and continuously updated, it is possible to enter an IP address which is known to be malicious and search for all domains that where seen in the past to resolve to that IP address. The passive DNS lookup in the example below shows how the IP address 211.253.30[.]211 is the target of two domains that obviously are used for Amazon domain squatting:
Reuse of TLS certificates
Many people still know TLS certificates under their previous name SSL certificates, although the latter was already deprecated back in 2011. Naming peculiarities aside, both terms refer to public key certificates and serve the same purpose:
- Allow a connecting client to validate that the target is authentic, i.e. that no man in the middle is pretending to be the real target. This is done by integrating a Certificate Authority’s (CA) attestation (basically the certificate’s hash encrypted with a trusted CA’s private key).
- Populate the public key a connecting client can use to encrypt its data exchange with the target.
Although companies could use TLS Interception to look into encrypted traffic in their corporate network and to spot malicious communication, many companies refrain from doing so. The reasons are manifold, starting with legal problems of monitoring employee behaviour. No matter what’s the reason, in every case, malware authors can greatly reduce the risk of being detected by encrypting their C&C traffic. Therefore, they install a TLS certificate on their C&C server so that the malware can use the certificate’s public key to set up an encrypted tunnel. This technique makes use of the second feature described above, but the first feature – target validation – is often neglected.
It is additional work to create and install a TLS certificate, especially if it is signed by a Certificate Authority. Although this has become much easier with services like Let’s Encrypt that validate anybody’s certificates for free, it nevertheless is a time investment which is not necessary for the malware to function and to send encrypted traffic. For this reason, malware authors sometimes create only one certificate and reuse that certificate on other C&C servers. Of course the certificates are not valid for these other servers (or are self-signed anyway), but the malware does not check the validity, it simply wants to have the public key to start encryption.
Security analysts can leverage this reuse of the very same certificate: Due to the nature of public-private key cryptography, only the party who created the certificate will possess the private key to decrypt that traffic. As long as no other attacker obtains possession of that private key, it can be quite safely assumed that another server where the same certificate was reused also belongs to the same threat actor.
Using tools like Censys.io certificate search, analysts can find other servers where the same TLS certificate was reused. On these other servers, analysts might be able to find more information on the identity of the attackers. At the same time, domains found in such a certificate search can also be fed back into a threat intelligence database and flagged as potentially dangerous. This technique was for example used to discover hosts of APT group Fancy Bear (APT28).
Reuse of virtual environments or code
Professional threat actors do not work very differently from legal companies. The main difference in fact is only that the business they engage in is considered illegal by most constitutions. What both, legal and illegal ventures have in common is the strive for efficiency to maximize profits.
Attackers who set up C&C servers might do so by installing a pre-assembled virtual machine that hosts all necessary software. The combination of tools, software versions, VM metadata etc. can serve as a unique fingerprint for that specific attacker. If such a custom VM is reused on different C&C servers, it is a sign that the same group of threat actors is running that instance (although it could be faked of course). The same is true if the malware authors wrote their own programs and reuse these as a whole or in parts: Similarities in code can equally serve as fingerprints. This technique was for example used by Kaspersky Labs and others to analyse WannaCry. They found code that previously had been employed by North Korean hacker group Lazarus.
A more recent trend is that APTs resort to standard software and commodity cloud infrastructure. This has at least two benefits: They save on development costs, because somebody else already wrote the tools; second, attribution becomes much harder, because with standard software running on mass market cloud infrastructure, there is no obvious unique fingerprint that analysts could employ to search the web for other C&C servers running the same uniquely identifiable setup. Of course, you could still try to create a fingerprint based on the specific combination of tools that the attackers used. However, with an increase in living off the land attacks, where no additional tools are installed and only omnipresent standard tools are used for less benign purposes, this becomes more and more difficult. In September 2020 for example, Microsoft shut down several maliciously used Azure cloud instances attributed to hacker group Gadolinium (APT40).
IP addresses in C&C server logs
Let’s finish with one of the more straightforward methods of attribution: If analysts have the possibility to access the C&C server and read the server logs, they might be able to find IP addresses that lead to the attackers’ real identity. Depending on the log retention time of the server, it might be possible to retain the IP addresses which were used to initially set up the C&C server. In some cases, attackers did not use proxies or additional hops to obfuscate their identify, but directly connected to the server. If the ISP that administers the respective IP address is willing to cooperate, it is possible to see which individual was assigned that specific IP address at the given time. Cooperation on behalf of the ISP is of course not guaranteed in cross-border investigations, for example if a US entity is trying to get information from a Chinese ISP.
Bibliography
- About WHOIS | ICANN WHOIS. (n.d.). Retrieved 29 September 2020, from https://whois.icann.org/en/about-whois
- Advanced persistent threat. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Advanced_persistent_threat&oldid=980300474
- AlienVault—Open Threat Exchange. (n.d.). AlienVault Open Threat Exchange. Retrieved 29 September 2020, from https://otx.alienvault.com/browse/global?include_inactive=0&sort=-modified&page=1&indicatorsSearch=modified:%22%22
- Associated Press. (2020, September 17). German Hospital Hacked, Patient Taken to Another City Dies. https://www.securityweek.com/german-hospital-hacked-patient-taken-another-city-dies
- Bitcoin. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Bitcoin&oldid=980584476
- Censys. (n.d.). Censys. Retrieved 29 September 2020, from https://censys.io/certificates
- Certificate authority. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Certificate_authority&oldid=977429655
- Cichonski, P., Millar, T., Grance, T., & Scarfone, K. (2012). Computer Security Incident Handling Guide: Recommendations of the National Institute of Standards and Technology (NIST SP 800-61r2; p. NIST SP 800-61r2). National Institute of Standards and Technology. https://doi.org/10.6028/NIST.SP.800-61r2
- Command and control. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Command_and_control&oldid=977698547
- Cybersquatting. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Cybersquatting&oldid=975325824
- Domain Name System. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Domain_Name_System&oldid=978575155
- Dynamic program analysis. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Dynamic_program_analysis&oldid=934903597
- Enabling or disabling privacy protection for contact information for a domain—Amazon Route 53. (n.d.). Retrieved 29 September 2020, from https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/domain-privacy-protection.html
- Fake Login Pages Spoof Over 200 Brands. (2020, August 24). IRONSCALES. https://ironscales.com/blog/fake-login-pages-spoof-prominent-brands-phishing-attacks/
- Fancy Bear. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Fancy_Bear&oldid=978514095
- Finding Nemo(hosts). (2017, July 21). ThreatConnect | Intelligence-Driven Security Operations. https://threatconnect.com/blog/finding-nemohost-fancy-bear-infrastructure/
- Ghidra. (n.d.). Retrieved 29 September 2020, from https://ghidra-sre.org/
- IBM X-Force Exchange. (n.d.). Retrieved 29 September 2020, from https://exchange.xforce.ibmcloud.com/
- IDA Pro – Hex Rays. (n.d.). Retrieved 29 September 2020, from https://www.hex-rays.com/products/ida/
- Let’s Encrypt—Free SSL/TLS Certificates. (n.d.). Retrieved 29 September 2020, from https://letsencrypt.org/
- Malware Hunter. (n.d.). Retrieved 30 September 2020, from https://malware-hunter.shodan.io/
- Mandiant. (2013). APT1—Exposing One of China’s Cyber Espionage Units. https://web.archive.org/web/20130219155150/http://intelreport.mandiant.com/Mandiant_APT1_Report.pdf
- Pastebin.com—#1 paste tool since 2002! (n.d.). [Paste Site]. Pastebin.Com. Retrieved 29 September 2020, from https://pastebin.com/
- Pernet, C. (2018, March 12). InfoSec Guide: Taking Down Fraudulent Domains (Part 2) – Security News – Trend Micro USA. https://www.trendmicro.com/vinfo/us/security/news/cybercrime-and-digital-threats/infosec-guide-taking-down-fraudulent-domains
- Public key certificate. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Public_key_certificate&oldid=978864991
- Quad9 DNS: Internet Security and Privacy in a Few Easy Steps. (n.d.). Quad 9. Retrieved 29 September 2020, from /
- Rascagneres, P. (2013). APT1: Technical backstage. 48.
- RiskIQ PassiveTotal Threat Detection & Investigation Platform | RiskIQ. (2020, July 20). https://www.riskiq.com/products/passivetotal/
- Second-level domain. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Second-level_domain&oldid=975294037
- Self-signed certificate—Wikipedia. (n.d.). Retrieved 29 September 2020, from https://en.wikipedia.org/wiki/Self-signed_certificate
- Solon, O. (2017, May 15). WannaCry ransomware has links to North Korea, cybersecurity experts say. The Guardian. https://www.theguardian.com/technology/2017/may/15/wannacry-ransomware-north-korea-lazarus-group
- Static program analysis. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Static_program_analysis&oldid=980828056
- Steffens, T. (2020). Attribution of Advanced Persistent Threats: How to Identify the Actors Behind Cyber-Espionage. Springer Vieweg. https://doi.org/10.1007/978-3-662-61313-9
- The HTTPS interception dilemma: Pros and cons. (2017, March 8). Help Net Security. https://www.helpnetsecurity.com/2017/03/08/https-interception-dilemma/
- Transport Layer Security. (2020). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Transport_Layer_Security&oldid=980090292
- Trend Micro. (2012). Luckycat Redux: Inside an APT Campaign with Multiple Targets in India and Japan. 26.
- Ulikowski, M. (2020). Elceef/dnstwist [Python]. https://github.com/elceef/dnstwist (Original work published 2015)
- Web Filter Lookup | FortiGuard. (n.d.). Retrieved 29 September 2020, from https://www.fortiguard.com/webfilter
- Whois.com—Free Whois Lookup. (n.d.). Retrieved 29 September 2020, from https://www.whois.com/whois/
- X-Force IRIS. (2020, September 3). Dridex Analysis Report—Malware Analysis IRIS Report. https://exchange.xforce.ibmcloud.com/malware-analysis/guid:a214dbe77981568310691adfbd365f23
- zvelo. (2020, August 11). (DGAs) Domain Generation Algorithms | What You Need to Know. Zvelo. https://zvelo.com/domain-generation-algorithms-dgas/